Perl の hash 操作。
なぜかよく忘れるのでメモ。
# hash の key と value を
# それぞれ変数にバインドするときは each 関数を使う
my %hash = ("key1" => "value1",
"key2" => "value2",);
while (my ($key, $value) = each %hash) {
# ...
}
# hash の中に目的の key が存在するかは
# exists 関数を使う
if (exists $hash{"key1"}) {
# hash から key を削除は delete 関数
delete $hash{"key1"};
}
#Perl #hash #each #exists #delete
SN 2013/07/08 01:19:53
Archives > Perl_hash_and_functions.html

sort コマンドだと、日本語などのマルチバイト文字を無視してソートしてしまうので、Perl でこんなスクリプトを書いておいて、msort なんかのコマンドとして保存しておくと便利。
#! /usr/bin/perl
use warnings;
use strict;
my @lines = ();
while (<>) {
push @lines, $_;
}
foreach my $line (sort @lines) {
print $line;
}
このやり方だと複数のファイルを読み込んだとき、全部をひとつの配列に突っ込んだ上でソートしてる。
#Perl #Shell #sort
SN 2013/07/08 01:04:13
Archives > Perl_multi_sort.html

Perl で URL の HTTP Status (200 OK とか 404 Not Found とか)を確認する。
#!/usr/bin/perl
use strict;
use warnings;
use LWP;
use HTTP::Status;
my $ua = LWP::UserAgent->new();
sub get_http_status {
my ($url, $ua) = @_;
return unless $url or $ua;
my $response = $ua->head($url);
my $msg = status_message($response->code);
return $msg;
}
my @urls = qw( http://basicwerk.com/
http://basicwerk.com/memo.cgi
http://basicwerk.com/contact.html
http://basicwerk.com/not_found.html);
foreach my $url (@urls) {
print "$url\t";
print get_http_status($url, $ua);
print "\n";
}
# 出力結果はこんな感じ
# http://basicwerk.com/ OK
# http://basicwerk.com/memo.cgi OK
# http://basicwerk.com/contact.html OK
# http://basicwerk.com/not_found.html Not Found
例えばこれを任意の URL を引数に受け取って結果を返す get_http_status.pl のようにするなら、@urls の部分を @ARGV に置き換えて、
#!/usr/bin/perl
use strict;
use warnings;
use LWP;
use HTTP::Status;
my $ua = LWP::UserAgent->new();
sub get_http_status {
my ($url, $ua) = @_;
return unless $url or $ua;
my $response = $ua->head($url);
my $msg = status_message($response->code);
return $msg;
}
foreach my $url (@ARGV) {
print "$url\t";
print get_http_status($url, $ua);
print "\n";
}
$ chmod 0755 get_http_status.pl
$ get_http_status.pl http://basicwerk.com/ http://basicwerk.com/not_found.html
http://basicwerk.com/ OK
http://basicwerk.com/not_found.html Not Found
#Perl #LWP #HTTP::Status
SN 2013/07/06 14:53:09
Archives > Perl_get_http_status.html
文字列補間について
例えば Perl で
my $score = 10000;
print "Your Score is ${score}!\n";
# -> Your Score is 10000!
みたいなことって良くすると思うんですが、Gauche だとこんな感じ。
(define score 10000)
;; print に複数の引数を取って
(print "Your Score is " score "!")
;; -> Your Score is 10000!
;; format で
(format #t "Your Score is ~a!\n" score)
;; -> Your Score is 10000!
;; 文字列補間!
(print #`"Your Score is ,|score|!")
;; -> Your Score is 10000!
;; シンボルの前後が空白なら | は不要
(print #`"Your Score is ,score")
;; -> Your Score is 10000
#Gauche #Scheme #Lisp #Perl
SN 2013/06/30 02:32:00
Archives > Gauche_Symbol_in_String.html

2013/06/28
本 MEMOMEM のキーワードをサマったグラフ。
HTMLタグを検索から除外。
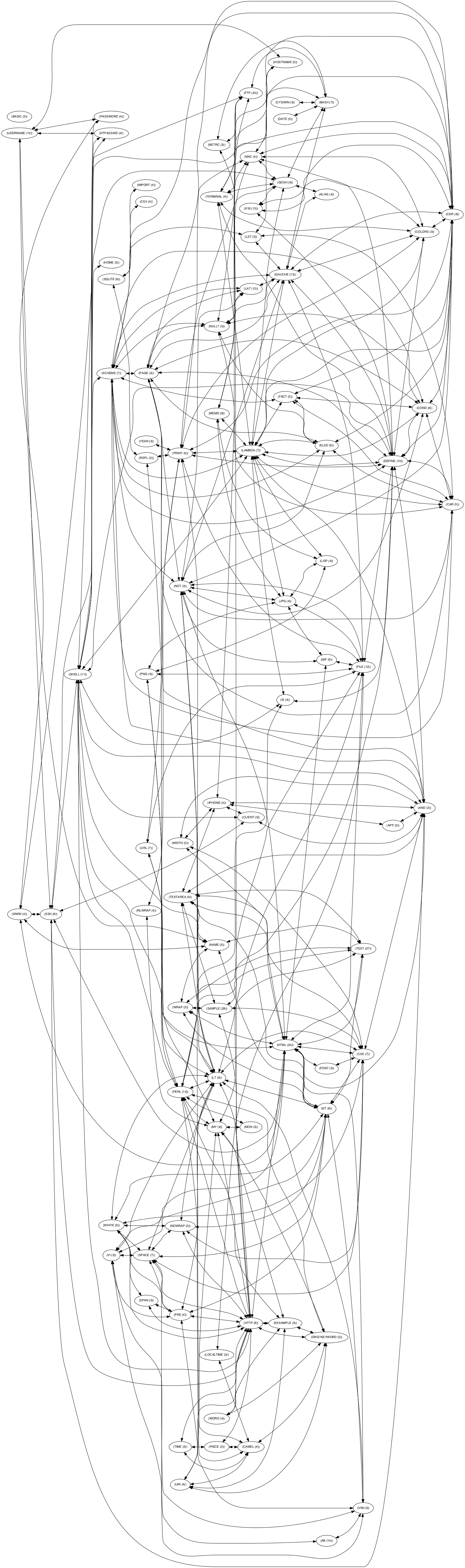
個人的なメモ
- tags.pl
- CLISP で png 書き出し
- そのまま jpg で書き出す
- image フォルダに top.jpg として保存(CSS で 1100px に縮めてる)
参考:
Graphviz - 簡単な使い方
http://reddog.s35.xrea.com/wiki/Graphviz.html
Graphvizで日本語を使う (Graphviz version 2.26.3)
http://d.hatena.ne.jp/simply-k/20100705/1278326617
画像処理についてあれこれ - Graphvizでノードのフォントサイズを指定する
http://kyle-in-jp.blogspot.jp/2011/01/graphviz_24.html
#Graphviz #Lisp #CLISP #Perl
SN 2013/06/28 10:00:10
Archives > 20130628_top_image_archive.html
© 2008-2013 Basic Werk