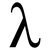
;; CLISP でのマルチバイト文字 [1]> (char-code #\a) 97 [2]> (char-code #\あ) 12354 [3]> (code-char 12354) #\HIRAGANA_LETTER_A [4]> (char-code #\心) 24515 [5]> (code-char 24515) #\U5FC3 [6]> (ext:convert-string-to-bytes "中村心" charset:utf-8) #(228 184 173 230 157 145 229 191 131) [9]> (ext:convert-string-from-bytes #(228 184 173 230 157 145 229 191 131) charset:utf-8) "中村心" [10]> *terminal-encoding* #<ENCODING CHARSET:UTF-8 :UNIX> [11]> (setf *terminal-encoding* charset:utf-8) #<ENCODING CHARSET:UTF-8 :UNIX> [12]> *default-file-encoding* #<ENCODING CHARSET:UTF-8 :UNIX> [13]> (setf *default-file-encoding* charset:utf-8) #<ENCODING CHARSET:UTF-8 :UNIX>
参考:
Common Lisp と日本語 - LISPUSER
#CommonLisp #Lisp #CLISP #encode #char-code #code-char #ext:convert-string-to-bytes #ext:convert-string-from-bytes
SN 2013/07/22 13:36:35
Archives > CommonLisp_study_02.html