最近、友人がプログラマを目指し始めたり、うちのチームメイトと話していてもプログラミング関連の話題がちょいちょい出てきたり(子供にプログラミングを教える教室があるとか、EC業界には圧倒的にプログラマが不足しているとか)。
それに、僕自身気がつけば最初にプログラマという職業に就いたのがちょうど10年前だなぁと思ったりしたので、少しプログラミングについて書いてみる。
以前書いた プログラミングの始め方 の続編的な感じで、ちょっとだけ実際のコードや用語も出てくる。
もう一度、流行り廃りについて
プログラミングに使う言語や環境にもファッションと同じように流行り廃りがある。
以前の記事「プログラミングの始め方」 でも「情報に惑わされるな!」と書いたけど、結論から言うとこれは気にしなくていい。
それにだ。まずもって、周りと比べることによって優越感に浸ったり、逆に劣等感を感じたり、つまりメンタルが周りの状況に極端に左右されるような人はプログラマに向かない。
なぜ流行り廃りを気にしなくていいか?
それはどのプログラミング言語も「機械語を直接書くのはしんどいから自然言語に似せてみました」という点では同じだからだ。
もう一つ、プログラミング言語には個性がある。向き不向きと言ってもいい。
どんなに流行っているからといって、Web用に最適化された言語で組込系のシステム(例えば家電とか医療機器の中で動いているプログラム)を書こうと思う奴はいない。
ある分野に特化した仕事にプログラマとして採用されたなら、流行り廃りに関係なくその言語のプロになるしか無い。
つまり、現在まっさらな状態でこれからプログラミングを勉強しようとするなら、「俺は PHP 一本で食っていくんだ!」なんて考えないほうがいい。
どれでもいいから好きな言語、なんとなく親しみが感じられる言語を選んで勉強し始めてみよう。
そして大事なのは、プログラミングが動いている原理や各言語の根本的な「思想」とでも呼べるような部分を覗いてみること。
一旦内部的な仕組みを理解してしまえば、大きな括りで「プログラミング」というカテゴリーの中を自由に動き回れる(仕事も選びたい放題だ!)。
プログラミング言語に個性があること以上に、人間にはもっとのっぴきならない個性がある。そう、好き嫌いだ。
自分の「好きな」「得意な」分野で働きたいなら、世の中の流行り廃りに敏感になるよりも、
- プログラミングの仕組みを理解すること(言語のインターフェースに左右されないようにすること)
- お気に入りのプログラミング言語と出会うこと
この2つが大事だと思う。
どちらも身体で感じることであったり、運であったりする。だから、全く急ぐことも焦ることもない。
どこにでも出てくる考え方
どんなプログラミングをやっても必ずと言っていいほど出くわす考え方がある。
以下は(全部は無理だけど)いくつか掻い摘んで説明してみる。
これはあくまでも僕の個人的な経験に基づいて、特定の言語によらずよくよく理解しておくべき事柄だと思うものを挙げる。
変数とスコープ
大昔、今のような自然言語(主に英語)に似せたプログラミング言語が出始めた頃までは「プライベートなデータ置き場(変数)」なんて仕組みはどの言語にもなかった。
データを蓄えた「変数」と呼ばれるパラメータは「全部」、みんなが自由に参照したり書き換えたり出来る場所に置かれていた。
ところが、プログラマが増えたり、複数人でひとつのアプリケーションを作るようなケースが増えたりした結果、この実装が深刻なバグを生むようになった。
人間の仕事に置き換えて想像してみるといい。
何でもかんでもシェアフォルダに置いて、情報を共有しながら働いているチームがあったとしよう(いや、実は意外にこういうチームは多いのだけど・・・)。
チーム内の「認識」や「ルール」、呼び方はなんでもいいけど、要は口約束で「クライアントごとにエクセルファイルは新規作成する」という決まりがあったとする。
しかしだ、そこに僕みたいな雑な考え方の新人が入ってきたとして、不用意に既存客のファイルをコピペして新しい顧客用のエクセルを作成したとしよう。
するとこんなことが起こる。顧客ごとに細かく設定すべきパラメータもそのままコピペされるのだ!
これによって、顧客は契約した覚えのない金額が毎月何故か請求されたり(そしてそれに気づかず払ってしまったり!)なんていう「バグ」が発生する。
このチームのやり方ではこの種のバグは根本的に潰せない。なぜなら仕組み自体が「口約束」の上に成り立っているからだ。
同じやり方を続けているうちは僕みたいにズボラな新人が入ってくる度に予想外のバグに見舞われることになるだろう。
そこで人間の曖昧な記憶や習慣に頼らず、システム的に情報の見える範囲を制限しようというのが、プログラミングでいうところの「プライベートなスコープ(有効範囲)を持つ変数」という考え方だ。別名「レキシカルスコープ」「レキシカルな変数」なんて言ったりする。
だからプログラミングを勉強するときは、その変数が「見える」範囲はどこまでで、その範囲の違いによってどんな風に呼び分けてるのか(どこからでも見える変数のことを言語によって「グローバル変数」と言ったり「スペシャル変数」と言ったりと呼び方がバラバラなんだ)を理解しよう。
特にグローバルな変数は言語の実装によってプログラミングのコンテクストに載った時に動作がまちまちだ。
そういう込み入った内容のテキストを読み下すときに「あ、これはグローバル変数のことを言っているのだな。そしてこれはこのスコープに出くわした時の挙動を説明しているのだな」と理解しながら読むのと、連なる横文字に踊らされながら狐に化かされた思いをするのとでは大きな違いがある。
スタック
データは連なることが多い。
例として商品を管理するプログラムを考えてみよう。
何もかもが全然違う商品を、しかも両手の指で足りるほどの商品数しか扱わないなら、商品を管理するプログラムなんて要らない。メモ帳で十分だ。
たいてい商品ていうのは少しずつだけど違った属性(製造年、色、容量などなど)を持っていて、それがものすごい数の種類だったり数量だったりするから人間の頭でおぼえるのはやめてソフトウエアを買おうという発想になる。
つまりこの状況をプログラムに直すと、少しずつパラメータの違うデータを一連なりのセット状態で扱うってことだ。
(ここからオブジェクト指向の話には行かない。これはあくまで例だ。ちょっと脱線すると、オブジェクトやクロージャも連続して処理する時には結局シーケンスがそれぞれのポインタを格納して連続的に処理することになるでしょ?)
データが列をなして重なった状態を「スタック」という。
プログラムを勉強していると「先入れ先だし(First In, First Out を略して FIFO なんて言ったりする)」とかいう表現に出くわす。
これがスタックだ。スタックには通常入り口と出口は1つずつしかないから、挿入したデータがいつ取り出せるかは実装やメソッドによって異なる。
さて、このスタック型の変数にも言語ごと、その特性ごとにいろんな呼び方がある。
配列と言ったり、ベクタやベクトルと言ったり、そのままスタックと言ってる言語もあるし、ひっくるめてシーケンスという呼び名を使う言語もある。
いずれにしろ共通しているのは「番号付きの(=順番のある)データの列」ってことだ。
よくプログラミングの解説書では初歩的な変数の話を終えた後に配列の話を始める本が多いようだ。
確かに配列も変数と同じように宣言したり書き換えたり、また、そのやり方もプリミティブな変数に対するそれと同じようだったりするから変数の一種という考え方でも、仕事上はほとんど問題はない(これはオブジェクトや関数もいっしょ)。
だけど根本的に理解しなきゃいけないのは、配列とはデータそのものを格納したものじゃなくて、データを並べるための「方法」または「構造」だってことなんだ。
スタック、配列、ベクタ、シーケンス、呼び方はなんでもいいけど、こいつらがデータそのものじゃなくて「順番のある構造」という概念を表現するための言葉だと分かると、専門書の言ってることも飲み込みやすくなるだろう。
そもそもプログラミング言語自体がデータを扱うための「考え方」を言語化したものなんだ。
このスタックという考え方ひとつ取っても、その言語の特性や思想みたいなものが顔を出すことがあるから面白い。
この記事では取り上げないけど、オブジェクトやクロージャと呼ばれるものも、それぞれあるやり方を使ってデータを保持するための構造に名前を付けたものだ。
「なんでそうやっていろんな構造を作って新しい名前を増やしていくのか?」と初心者の頃は誰でも頭を抱える。
そういう時はこう考えてみよう。
- どんな名前にしろ、なにか一塊の概念を呼びやすくするために付けられた呼び名(エイリアス、ショートカット、シンボルと言い換えてもいい)に過ぎない
- その概念にこれだけ(専門書の)ページが割かれてるってことは実に便利なものに違いないのは確かだ
- でも、ちょっと待てよ。これは今の自分が乗り越えなきゃいけない仕事上の問題解決に必要だろうか?これ無しじゃ解決できない部分はあるだろうか?
- これ無しでも仕事ができるなら(もしくはその概念を使わないほうがずっとシンプルに問題が解決できるなら)後で暇な時にでも勉強しよう
ここで理解を後回しにすることを恐れちゃいけない。その言語を使って仕事をしていたらいずれ分かることなんだから。
複雑な概念にかかずらって普通のことが疎かになるより、単純なことを上手に丁寧にできるようになることのほうが先決だってことを覚えておこう。
真、偽、そして未知
どのプログラミング言語にも「述語」と呼ばれる関数やオペレータがある。
述語とは、与えられた引数(アーギュメント)が Yes か No かを判断して返す。
日本語で言うと文末に来る「である」「ではない」に相当する。英語で言えば「is」「is not」だ。
例えば、あるエンジニア(引数)がフリーのエンジニアかどうか返す述語(これを仮に is_free という関数で定義しよう)があるとする。
エンジニアを eng という名前の変数に格納して is_free に渡す。
さっき話した配列の変種で連想配列というのを辞書代わりに使ってフリーかどうかを判断しよう。
(連想配列とは key と value を一組にして保持する。もうちょっと言うと、名前には「配列」って付くけど、実は順番は関係ない。)
Perl で書くならこんな感じだろう。

#! /usr/bin/perl
use warnings;
use strict;
my %engs = ("Kohei Hamochi" => 0,
"Shin Nakamura" => 1,);
sub is_free {
# この $eng はこの後出てくる同じ名前の
# $eng とは異なり、このサブルーチン内だけで
# 有効な(つまりレキシカルな)変数だ
my $eng = shift;
# 連想配列からエンジニアの名前($eng これが key)を
# 使って対応する value を取り出す。
my $value = $engs{$eng};
# 返す
return $value;
}
# この $eng はここでの宣言以降、どのスコープでも
# 有効な変数になる
my $eng = "Shin Nakamura";
if (is_free($eng)) {
# Yes
print "$eng is free engineer.\n";
}
else {
# No
print "$eng is not free engineer.\n";
}
# -> key が "Shin Nakamura" なので
# Yes のスコープにある文が実行される
同じ処理をCommon Lisp で書くとこうだ。
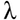
;; 連想配列を alist で定義
(defparameter engs
'(("Kohei Hamochi" . nil) ("Shin Nakamura" . "free")))
;; assoc 関数で alist 内の要素にヒットするか確認
;; リストの value 部分を返す
(defun is_free (eng)
(cdr (assoc eng engs :test #'string=)))
(let ((eng "Shin Nakamura"))
(if (is_free eng)
(format t "~A is free engineer.~%" eng)
(format t "~A is not free engineer.~%" eng)))
;; -> Shin Nakamura is free engineer.
述語の役割がだいたい想像できただろうか?
実際には eng 変数のところに次々といろんな値が嵌めこまれてそれぞれの値について調査した結果を返すようなプログラムに発展していくだろう。
engs で定義した辞書ももっと膨大なものになるかもしれないし、それは外部のデータベースになったり、はたまた、検索されるたびに増改築されるような仕組みが組み込まれるかもしれない。
また、Perl のサンプルの方に詳しくコメントを書いたけど、こんな短いプログラムの中にも、今まで話した変数、スコープ、配列などなどのアイデア・仕組みが自然に盛り込まれている。
さて、本題に入ろう。
実は Perl のサンプルの書き方をちょっと変えると、関数 is_free に対して辞書にない名前を渡したときにエラーが生じる。
#! /usr/bin/perl
use warnings;
use strict;
# そのまま
my %engs = ("Kohei Hamochi" => 0,
"Shin Nakamura" => 1,);
# そのまま
sub is_free {
my $eng = shift;
my $value = $engs{$eng};
return $value;
}
# わざと連想配列にない key
my $eng = "aaa";
# 条件分岐に先立って結果を格納
my $result = is_free($eng);
if ($result) {
# Yes
print "$result : $eng is free engineer.\n";
}
else {
# No
print "$result : $eng is not free engineer.\n";
}
# -> key が見当たらないので、
# リターン値が未定義(undefine)
# Use of uninitialized value $result in concatenation (.) or string at ./this_program.pl line n.
# : aaa is not free engineer.
未定義(undefined, undef)とは言い換えれば「未知」ということだ。
つまり Perl では、真(1 とか -1 とか "foo" とか、(1) とか、true とか)、偽(0 とか "" とか、() とか、false とか)の2種類の判定基準の他に未定義(undef)も考慮した実装が必要だ。
これに対して Common Lisp のような言語では、真(T)と偽(NIL)の2つしかない(言い換えれば NIL 以外は全て T)。
なので例えばもし Perl のような言語の考え方のまま、Common Lisp でこんなコードを書いてしまうと思わぬエラーを引き起こす。
;; alist の value が先ほどと違っていることに注意
(defparameter engs
'(("Kohei Hamochi" . 0) ("Shin Nakamura" . 1)))
(defun is_free (eng)
(cdr (assoc eng engs :test #'string=)))
;; Kohei Hamochi はフリーエンジニアではないが・・・
(let ((eng "Kohei Hamochi"))
(if (is_free eng)
(format t "~A is free engineer.~%" eng)
(format t "~A is not free engineer.~%" eng)))
;; Common Lisp では 0 は偽でないので
;; なんと結果は
;; -> Kohei Hamochi is free engineer.
このように、言語の体系によって真偽・未知の捉え方、定義は異なる。
つまり、データ上での値の入れ方や、述語を定義するときの処理の書き方など、様々なところに違いが生じる。
ここで真偽値の違いを吸収するためのベストプラクティスについてあれこれ議論するつもりはない。
面白いのは(そう、面白いのは)自分が習得しようとしている言語の思想や構造を理解して、自分でベストプラクティスを見つけるプロセスそのものなんだ。
プログラミングを勉強するプロセスを楽しめるような工夫をいつも試行錯誤しよう。単なる丸覚えや他人が書いたコードのコピペでプログラムを組み上げていくほどつまらないことはない。
文法のはなし
例えば「等しいかどうか」を判別する「EQUAL」。
こいつも前節で出てきた述語の一種。
そして前節の真偽値同様、この「EQUAL」も言語によっていろんな書き方がある。
それに、たいていその書き方の違いで比較の厳密さや、比較対象を選択するように設計されている。
ここで覚える必要はないけど、ちょっと具体例を示そう。
「EQUAL」は算数で習った「=」のことだ。
この「=」という記号を算数の教科書通り「等しい」という意味で組み込んでいるプログラミング言語は、実は少数派かも知れない。
先ほどの Perl もそうだけど、変数への値の代入に「=」を使ってしまっている言語では、「等しいかどうか」を確認する述語に「=」はもう使えない。
だから「==」や「eq」など、「等しいかどうか」用のオペレータが別に用意されている。
でも、Common Lisp のような言語は「=」がそのまま「等しいかどうか」を確認するのに使える(代入には「=」とは別のやり方が用意されてる)。
ただし、Common Lisp 中の「=」は数値を比較する「専用」の述語だ。
その他のもの(シンボルや文字列など)を比較して「等しいかどうか」を検査するにはそれぞれ別の述語が用意されている。
「=」以外にどんなのがあるかというと、「eq」「eql」「equal」「equalp」「string=」・・・と、なんで?と思うかもしれないがたくさんの「EQUAL族」が存在する。
こいつらの違いは「なにをどう比較するか」なんだ。比較する対象と比較の仕方で述語を使い分ける。
このように「EQUAL族」だけでもたくさんの種類がある(言語ごとに表記が異なり、かつ、言語内での定義の違いで同じようだけどちょっとずつ違う複数の種類が存在する)。
ここまでの話を読んでみて、学校で習ったある教科を思い出さないだろうか?
そう、文法だ。
プログラミング言語は、自然言語に比べるとずっとずっとシンプルで厳密な文法の上に成り立っている。
だからネイティブじゃない日本人が英語を話せるようになるよりも、英語ベースのプログラミング言語をマスターするほうが(文法上は)ずっと簡単なんだ。
ただし、自然言語と大きく違う点は、文法を無視できる自由さが「全く無い」ところ。
プログラムのソースコードの中では、コメントアウトされた部分以外で無駄な文字は一文字もない。空白や改行でさえ意味がある。
何が言いたいかというと、「eq と equal って、なんか字面も似てるし、たいして差なんてないでしょ?」という浅い理解でめちゃくちゃな使い方をしていると簡単にバグだらけのプログラムができちゃうってことだ。
しかもこの種のバグは厄介だ。
「eq」でも「equal」でも置かれた場所的に(つまり構文的には)特に間違いじゃない場合、プログラムがエラーを吐くのは実行時、もっと悪いと何か特定の値に出くわしたときに限ってエラーになるかもしれない。
見つけやすくて、すぐに直せて、影響範囲が狭いバグはほとんどバグじゃないと言っていい。
本当に気をつけなくちゃいけないバグは前者の逆の性質を持ったやつだ(どこにあるかわからなくて、見つけても直すのにものすごい労力を必要とし、想像を絶するほど影響範囲が甚大なやつ)。
文法、オペレータ、関数、真偽値・・・これらプログラミング言語を構成する要素に対する浅い理解はバグにつながる。
プログラマが仕込んだバグはそのままビジネス上の損益につながるってことを肝に銘じておこう。
理論演算
もしあなたが数学の知識が殆どない状態でプログラミングの勉強を始めようとしているのなら、まずは集合論の簡単な解説書を読んでおくことを強く勧める(書店や図書館で実際に手にとって見てあなたの分かる言葉で解説してあるものを選ぶといい。理解したい中身はそんなに込み入った内容じゃない)。
この記事の前半でもちらっと触れたけど、プログラミング言語で書いたソースコードは最終的に機械語に翻訳される。
知っての通り、機械は 0 と 1 の世界だ。つまり無数の Yes と No を組み合わせて bit を操作していく。
最終ゴールは 0 と 1 のいずれかを選ぶわけだけど、その選択に至るまでのプロセスは理論演算の組み合わせでできている。
つまり自然言語に似せたプログラミング言語(専門用語で高級言語という)は、複雑に折り重なった理論式の操作を覆い隠して、人間が馴染みやすい「名前」の中に閉じ込めたものの集まりなんだ。
このことを知れば、理論式を導き出すための集合の理論を勉強しておくことが如何に重要か想像できるだろう。
とは言え、コツとして覚えておくことはそれほど難しいものではない。
代表的なものをひとつ紹介しておこう。
理論演算は短絡的だ
与えられた条件が全て真(True)かどうかを判別する理論式のオペレータ(理論演算子)に「AND」がある(言語によっては「&&」と書いたりもする)。
例えば次のような if 文があるとしよう。
if (false and true) {
print "OK.";
}
else {
print "NG.";
}
このプログラムが "OK." を印字することはない。
if の後のカッコの中に並べられたものが条件式だ。
条件式は左から右に向かって順に評価されていく。
false は評価されると偽(false)を返す。
AND は「条件全てが真のときに限って True を返す」から、一つ目の条件が偽(false)の時点で評価は false になる。
だから上のコード if (false and true) で and の後に置かれた true は評価すらされずにスルーされる。
故に AND は短絡的だ。
時々、if (false and true) であれば false も true も両方評価された上で AND が真偽を返すと勘違いしている初心者を見かける(そして、そう、自分が初心者だった頃に同じ過ちを犯したことがある)。
もう一度言う。理論演算は短絡的なんだ。AND だけじゃない、OR も XOR も同じだ。
理論演算子は答えが判った時点で条件の評価を止めて次のステップに移ってしまう。
ベン図なんかを使って、EQUAL、NOT、AND、OR、XOR なんかの基本的な理論演算を理解したら、後はこの短絡さを頭においておけばプログラミングの条件分岐を書くときに致命的なミスは避けられるだろう。
Outro
ざっといくつかのテーマに沿ってプログラミングの端っこを歩いてみたけど、どうだっただろうか?
プログラミングを勉強してみたいなと思ってる人(または、し始めたばかりの人)にとってちょっとでも参考になればと思う。
以下はプログラミングの言語の部分から一歩引いて、プログラミングを仕事にする上での僕のちょっとした考えを書いて終わりにしようと思う。
プログラミングはビジネスのほんの一部だ
プログラマ、つまりプログラミングを仕事にしたいならこのことが一番大事かもしれない。
プログラミング(コーディングとも言う)はビジネスにまつわる仕事全体のほんの一部でしかない。
プログラマだからといってプログラミングだけやってればお金がもらえると思ったら大間違いだ。
だからプログラミングを勉強している身分(つまりちょっと時間的に余裕がある身分)なら、ついでにビジネスのことも勉強しよう。
念願叶ってプログラマの職にありつけても、たいてい、その仕事がいずれつまらなくなる理由はビジネス上のことだったりする。
これは逆も言える。プログラマ的には望んだポジションじゃなくても、ビジネスとしてすごく面白ければ意外と楽しく仕事できるものだ。
だから「プログラマ」という肩書にこだわらずに、面白い仕事を探そう。
面白い仕事にプログラマとして就職できたら、プログラマであることは初日に忘れてしまおう!
「え?」と思うかもしれないが、現実世界ではこの方がいろんなことが上手く行く。
プログラマが持っているプログラミング上のテクニックは「ここぞ」という時に活かすから価値があるんだ。
いつでもどこでもコードを書きまくって、ビジネスを引っ掻き回したり贅肉だらけにしてるプログラマやSE、それにそういうポジション出身のマネジャーが多すぎる。
こういう連中はたいてい「俺は◯万行書いたぜ」とか「こんなデカいプロジェクトに参加したぜ」とか「俺の作ったWebサービスは毎日◯万人が利用してるんだぜ」なんていうどうでもいいことを自慢してくる。
はっきり言おう、プログラマとして幸せな人生を送るにあたって、それらにはなんの価値も無い。それどころかむしろ有害ですらある。
プログラマが時間なんぼの連中と一線を画しているのは、如何に短い時間や少ない労力で十分な金を手に入れるかに集中できるところだ。もっと言えばどれだけ潰さなきゃいけない時間を持て余すかがひとつのバロメータになる。
例えば営業職やサポート職をやっていた人が一念発起してプログラミングを勉強し、プログラマとしての職に就けたとする。
もしその新しいプログラミング職で以前よりも長い時間働き、以前よりも健康を害し、もっと悪いと以前よりも収入が減ってしまったなら、その転職にはなんの意味もない。
プログラミングという行為は、大前提として人を幸せにし、日々の仕事をよりクリエイティブにするためにあるってことを忘れちゃいけない。
あなたにとってプログラミングをマスターすることが、(不幸自慢するだけが取り柄のプログラマにならずに)幸せで充実した人生を送るきっかけになればと心から願う。
